*この記事は トレタ Advent Calendar 2020 の7日目の記事です。
こんにちは。トレタでサーバーサイドエンジニアをしている川村です。 この記事では自分の学習も兼ねてHTTP/3についてまとめたいと思います。
このテーマにしたきっかけと記事の目標
先月「QUICとHTTP/3がIETFのラストコール。RFCによる標準化が間近に」という記事を見て、「規格策定してることはなんとなく知ってたけど全然気にしてなかったな」と思っていたものの、全く調べてなかったのでこれを機に調べてみようとこのテーマにしました。
という入りなので、データ構造やシーケンスのような細かいレベルの話はでてきません。※細かい所は参考のリンク先を辿っていただけると見つかるかと思います
この記事ではHTTP/3で何がどう変わって何が良くなるのかを把握することを目標にします。
HTTP/3の背景
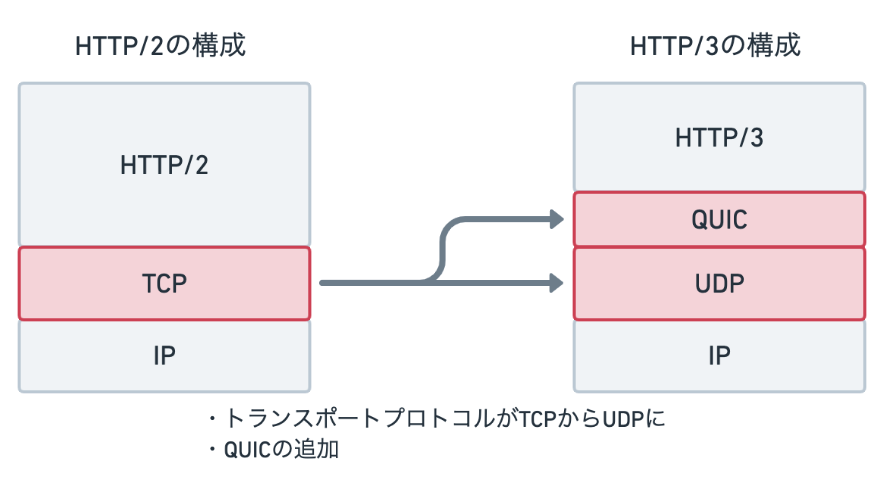
HTTP/3はQUIC上で動作するHTTPの規格として新たに策定されました。
HTTP/2をそのまま使えればよかったのですが、トランスポート層変更の影響により不都合があったので、HTTP/2をベースにQUICの上でも問題なく動作するよう作成されたのがこの規格です。
QUIC?
まずは、HTTP/3策定のきっかけとなったQUICとは何かから見ていきたいと思います。
QUICは、元をたどれば以下を目標にGoogleが作成したUDP上で動作するトランスポートプロトコルです。
- TCP上でHTTP/2を使用する場合の不都合を解消する
- 通信開始時の往復回数をへらす
HTTP/3とともに使われる予定のQUICは、Google版にあった独自仕様を一般的な実装に置き換えて策定が進められたIETF版のプロトコルとなっています。
〜 QUICの特徴 〜
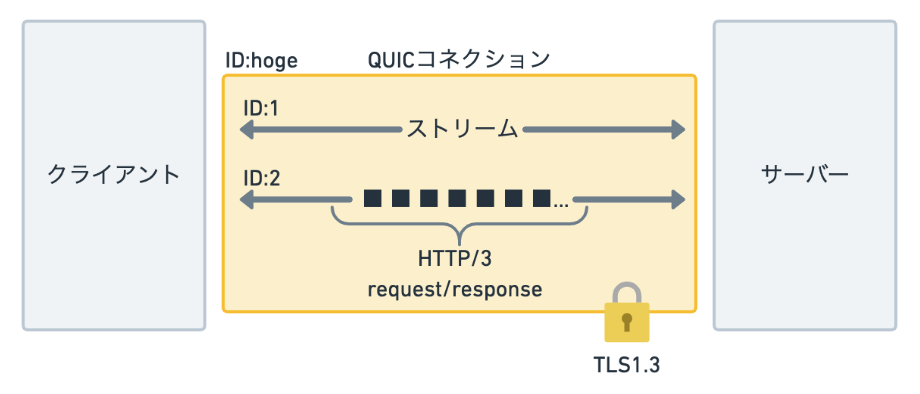
- ストリームの導入
QUICではHTTP/2にあったストリームの概念を取り入れており、以下のように動作します。
- 1コネクションに複数ストリームを流せる
- ひとつのストリーム内でのパケット到着順序は保証される。複数ストリーム間での順序は保証されない。
- UDPで動作する
TCPはプロトコルの仕様として、送られてきたパケットにロスが無いか検証し、ロスがあった場合再送信してもらうことができるようになっています。この仕様のおかげで、TCPを使っていれば確実に完全なデータを受け取ることができるわけです。
ところで、HTTP/2は1コネクションで複数のストリームを扱うことで、複数のファイルを並列に取得できるようにし、HTTP/1に比べて効率よくファイルを取得できるようになっているのでした。
HTTP/2はTCPで動作するため、コネクションでパケットのロスが発生するとパケットの再送待ちが発生します。 その結果、このコネクションで扱われている全てのストリームの処理がパケット再送までのあいだ止まることになってしまいます。(Head of Line Blocking)
UDPのプロトコル自体にはパケットロスを修復する仕様は含まれていないため、UDPを使うことでこのブロックを回避することができます。UDPで保証されない代わりにQUIC側にストリーム単位でパケットロスを修復する仕組みが用意されているので時々パケットがロスすることを受け入れるわけではありません。
- コネクションをID管理するためIPが変化してもセッションが継続できる
TCPではコネクションの識別に「送信元/先のIPアドレス+送信元/先のTCPポート番号」を使用しますが、QUICでは各コネクションにIDを割り振るため、クライアントのIPアドレスが変わった場合でもセッションを継続することができます。
- 0-RTT/1-RTTハンドシェイクの提供
ハンドシェイクはサーバー/クライアント間でコネクションを確立するために行う一連の処理のことです。
TCPでは接続が確立するまでに1往復半のやり取りが必要でした。(3-Way ハンドシェイク) QUICでは1往復のやり取りでコネクションを確立できる(1-RTT ハンドシェイク)ようになっており、同じコネクションを再開する場合は、再開メッセージと共にデータを送信することもできる(0-RTT ハンドシェイク)ようになっています。
これにより、HTTPリクエストの内容などアプリケーションとして送信したいデータをより早く送ることができるようになります。
- 暗号化が必須
QUICではTLS1.3による暗号化が必須となっています。 このため、HTTP/3による通信では暗号化されていない通信は存在しないことになります。
HTTP/3
はじめに書いた通り、HTTP/3はQUIC上でHTTP/2を使えるようにしたものです。 そのため、機能的にはHTTP/2とほぼ同じになっており、優先度制御以外の機能的な差分はQUICの仕様に対応させるために発生しています。
〜 HTTP/3と2の違い 〜
- HTTP/3ではストリームを扱わない
HTTPのレイヤーでストリームの管理をしないという意味です。
上述の通りQUICにストリームの実装があるので、HTTP/3ではQUICのストリームを使用して、HTTPのデータを送受信します。
- ヘッダーの圧縮にQPACKを用いる
HTTP/2ではHPACKという方式でヘッダーを圧縮していましたが、この方式はパケットロスが発生した場合、そのパケットが再送されてくるまで待つ必要があり、ブロッキングが発生してしまいます。 そこで、パケットロスの発生によりパケットの到着順序が入れ替わっても問題なく動作するようHPACKを改良したQPACKが利用されます。
- 優先度付けが無い
HTTP/2にあった優先度設定が複雑すぎ、サポートしているサーバーが現時点でもほとんどないことから、レスポンスの優先度設定はHTTP/3の仕様から外され、別途検討されることになりました。(HTTPヘッダーベースのものが検討されているようです。)
まとめと感想
ここまで見てきたことを元に、HTTP/3になるとどう変わるのかざっくりまとめるとこんな感じになります。
- 全体的に通信の効率が良くなる(これがおそらく一番の目玉)
- 確実に暗号化されていてセキュア
- うまくいかなかった優先度付けの仕組みが外部化されて単純になる
HTTP/2になったときもそうでしたが、アプリケーションを作成する上ではHTTP/3であるか否かを殊更気にすることはあまり無さそうという印象をもちました。
(優先度付けの仕様策定と実装が進めばパフォーマンスチューニングの観点で気にすることはあるかも。HTTP/3の仕様ではないのでこの記事のスコープからちょっと外れますが)
ただ、インフラ周りの設定をする際は、いままであまり使わなかったであろうUDPが来ることを意識する必要があるので少し注意が必要そうです。
調査した内容は以上です!何がどう変わったのか大体把握できたかなと思うので目標は達成しました。多分。
今回調査する機会を作ってくれた @hiroki_tanaka に感謝してこの記事を締めたいと思います🙇
ありがとうございました!
最後に定番のやつを...
もしトレタに少しでも興味を持っていただいた方がいれば、ぜひ遊びに来てください🙋♂️
仲間も募集しています!
参考
今回調べるにあたって参考にしたページです。
本文では簡単のため大分省略しているので詳細を知りたい場合はぜひ。
- HTTP/3 explained
https://http3-explained.haxx.se/ja - SEの道標
- 【図解】HTTP/3 (HTTP over QUIC) の仕組み〜UDPのメリット,各バージョンの違い(v1.0/v1.1/v2/v3)〜
https://milestone-of-se.nesuke.com/l7protocol/http/http3-over-quic/
- 【図解】HTTP/3 (HTTP over QUIC) の仕組み〜UDPのメリット,各バージョンの違い(v1.0/v1.1/v2/v3)〜
- ASnoKaze blog
- HTTP/3のヘッダ圧縮仕様QPACKについて QUIC HTTP HTTP ヘッダ圧縮 internet-draft
https://asnokaze.hatenablog.com/entry/2019/04/08/020017
- HTTP/3のヘッダ圧縮仕様QPACKについて QUIC HTTP HTTP ヘッダ圧縮 internet-draft
- The Cloudflare Blog
- HTTP/2優先度設定の機能向上によるWebの加速化
※文中には特に影響してないのですが、優先度付けってなんだ?という所で面白かったので載せておきます。
https://blog.cloudflare.com/jp/better-http-2-prioritization-for-a-faster-web-jp/
- HTTP/2優先度設定の機能向上によるWebの加速化
- Kazuho's Weblog
- HTTP のプライオリティが大きく変わろうとしている話(その他 IETF 105 雑感)
http://blog.kazuhooku.com/2019/07/http-ietf-105.html
- HTTP のプライオリティが大きく変わろうとしている話(その他 IETF 105 雑感)