Advent Calendar 2020 の 4 日目の記事です。
こんにちは、 wind-up-bird です。
前回に引き続き、ECS移行について書いていきたいと思います。
- 前編: 移行前の構成や課題、移行方針を記載しています。
- 後編: 移行後の構成や旧環境との変更点を記載しています。
※前編をまだ読んでない人は是非チェックしてみてね!
目次
新環境
この章では、ECS移行後の構成やデプロイ方法、移行方法を紹介していきたいと思います。
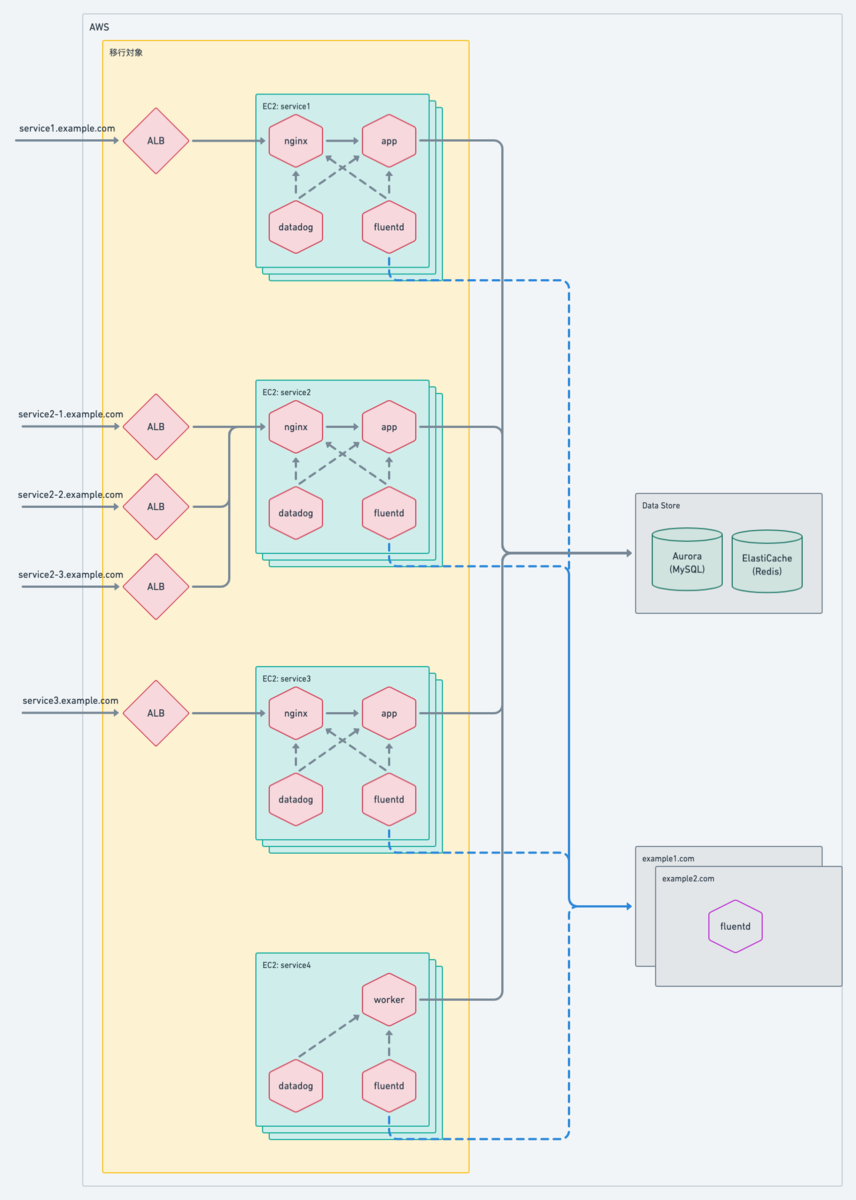
全体構成
全体的な構成は以下のようなイメージです。

1 つの ECS クラスター上に複数の ECS Service が稼働しており、API やウェブ予約、非同期処理など、各ロールが ECS Service に対応しています。
なお、プラットフォームは Fargate を採用しました。 これはマネージドサービスを採用することで、EC2レイヤーの管理が不要になることが主な理由です。
詳細

EC2 の場合と似ていますがプロセスではなく、各タスク内ではコンテナが起動しています。 また、用途はそれぞれ同じですが、 Fluentd ではなく、Fluent Bit を採用しています。(詳細は後述)
AWS のリソース管理
引き続き使い慣れている Terraform を利用します。
アプリケーションとは別に、インフラ用のレポジトリを新たに作成し、AWSのリソース管理はここで完結するようにしました。 ディレクトリ構成としては以下のように Module 化して、 呼び出し元で環境毎の差分を吸収しています。
├── environments
│ ├── production
│ │ ├── main.tf
│ │ └── remote-state.tf
│ └── staging
│ ├── main.tf
│ └── remote-state.tf
└── modules
├── service1 ※ECS の service1 で利用するAWSリソース
│ ├── acm.tf
│ ├── ...
│ └── variables.tf
├── common ※ECS で共通で利用するAWSリソース
│ ├── codepipeline.tf
│ ├── ...
│ └── variables.tf
├── ...
└── service4 ※ECS の service4 で利用するAWSリソース
├── appautoscaling.tf
├── ...
└── variables.tf
デプロイ
旧環境では、アプリケーションのデプロイは Capistrano を利用して EC2 へデプロイを実行していました。
今回の移行に伴って、デプロイパイプラインとして CodePipeline を新規に採用しました。 CodePipeline の内部では、 CodeBuild および CodeDeploy が動作します。

CodePipeline の各ステージでは、以下のようなことを行っています。
| ステージ | 説明 |
|---|---|
| Source | Github からアプリケーションのソースをダウンロードします。 |
| Build | Docker build (アプリケーションのbuild)、Image のタグ付け、ECRへイメージの push を実施します。 |
| Deploy | 作成された Image を利用して、 各ECSサービスにBlue/Greenデプロイを実施します。 |
なお、デプロイ開始と終了時には AWS Chatbot を利用して、成功/失敗の通知を Slack に流しています。
- 成功

- 失敗(例: 特定の CodeDeploy が失敗)

ロギング
旧環境では、ログのルーティングを目的として Fluentd プロセスが起動していました。 今回、ECSへの移行に伴い、Firelens (Fluent bit) を導入しました。*1 これは、 Fluentd よりも軽量であることが主な理由です。
挙動としては、アプリケーションのログファイル出力に対して、 Fluent Bit は tail input プラグイン を利用して取り込みます。 その後、タグに応じて CloudWatch のロググループに配送します。 また、Upstream として、 example1.com と example2.com のサーバ(EC2のときにも利用していたログの集約サーバ)を指定しています。
設定ファイルの主要な部分を抜き出すと、以下のようになっています。*2
- fluent-bit.conf
[SERVICE]
Flush 1
Grace 30
[INPUT]
Name tail
Path /path/to/a.log
Tag a.tag
[OUTPUT]
Name cloudwatch
Match a.tag
region ap-northeast-1
log_group_name ${A_LOG_GROUP_NAME}
log_stream_name a.$(ecs_task_id)
log_format json
[OUTPUT]
Name forward
Match a.tag
Upstream /upstream.conf
- upstream.conf
[UPSTREAM]
name forward-balancing
[NODE]
name aggregator-1
host example1.com
port 24224
[NODE]
name aggregator-2
host example2.com
port 24224
なお、Fluent Bit コンテナとアプリケーションコンテナは Fargate タスクストレージ を利用して、各コンテナで Volume マウントしています。
移行作業
上記の通り、移行先の環境が整ったので、移行作業です。
旧環境と新環境は並行稼動期間を設けて、Route53 の加重レコードを利用して徐々に切り替える方法を取りました。
- EC2:ECS = 100:0
- EC2:ECS = 99:1 (3日間様子見)
- EC2:ECS = 90:10 (3日間様子見)
- EC2:ECS = 50:50 (3日間様子見)
- EC2:ECS = 0:100 (1週間様子見)
というように徐々にトラフィックを新環境に向けていき、ユーザ影響を可能な限り最小化するようにしました。*3
最終的に、全く問題なく移行が完了しました。
と言えればよかったのですが、残念なことに移行先の設定ミスにより一部のサービスで障害が発生してしまいました。 しかし、これも最初の 3日間 の間に発覚したので、影響は最小限にすることができたのではないかと思います。
設定ミスを修正後、移行を再開し、その後は問題なく並行稼動期間を終えることができました。
最後、旧環境を削除して移行が完了しました。
ECS移行が完了した https://t.co/YbiIDcodC5
— wind-up-bird (@_windupbird_) 2020年11月18日
振り返り
ECSに移行してどうどうだったかまとめてみます。
Build 時間の短縮
Packer + Ansible がなくなり、代わりに Nginx と Fluent Bit の Docker イメージ作成のみとなりました。 これにより 30分以上かかっていたイメージの作成が2分程度で終わるようになりました。
EC2とOSの管理から開放された
ECS on Fargate を採用したので、EC2とOSを管理・運用する必要なくなりました。 また、Ruby の Runtime 、各サービス向けの設定ファイルはすべてアプリケーションレポジトリ単独で管理できるようになりました。 これによって、SREチームへの以来 => 作業待ちという状況も解消されました。
起動時間と費用
EC2 では起動に10分弱かかっていたのが、 ECS のタスク起動は1〜2分で完了するようになりました。 これにより、より柔軟にスケーリングポリシーを設定することができ、余剰なコンピューティングリソースの削減にも繋がりました。
結果として、33万円/月 程度の費用削減も実現できました。*4
ハマった点など
長々と移行について書いてきましたが、せっかくなので今回の移行で悩んだことやハマった点なども残しておこうと思います。
設定ファイルの管理
これは、ちょっと悩んだ点です。
前述の AWSリソースの管理はアプリケーションのレポジトリとは別に管理しています。
- レポA : アプリケーションのレポジトリ ( Ruby on Rails )
- レポB : インフラのレポジトリ ( Terraform )
では、この境界をどこにするのか?という点で少し悩みました。 具体的には、ECSのタスク定義や buildspec.yml ファイル、 appspec.yml はレポAで管理したほうがいいのか、それともレポBで管理するべきか?という感じです。
これは、ライフサイクルと役割という観点から、以下のようにしてみました。
- レポA : AWS のリソース上で "何を実行するか" を管理。
- 例: buildspec.yaml、 appspec.yaml、 タスク定義ファイルなどは、こちらで管理。
- レポB : AWS のリソース "そのもの" を管理。
- 例: ELB、 CodePipeline、ECSクラスタ、ECSサービスなどは、こちらで管理
これがベストではないかもしれませんが、環境変数やビルドの内容などアプリケーションの変更と連動するものは レポA に寄せたほうがよかろうと考えました。
ECS 標準デプロイアクション
これは少しハマった点です。
このブログでは詳細を記載していませんが、 トレタでは非同期処理として Sidekiq を利用しています。*5 このような ELB に紐付かない ECS サービスは当初 ECSの標準デプロイアクションを利用する予定でした。
具体的には、 CodePipeline の Build ステージで aws ecs register-task-definition を実行後、Deploy ステージで imagedefinitions.json を利用して、登録したタスク定義を反映する想定です。
しかし、 実際は、 アクション実行時にサービスに設定されているタスク定義のリビジョンを元に imagedefinitions.json に従って image プロパティのみを更新した
新しいタスク定義のリビジョンを作成するという挙動になります。
(つまり、 aws ecs register-task-definition で登録したタスク定義は使われない。)
解決策としては、
- Build ステージでタスク定義を更新後、
aws ecs update-serviceを実行する。 - CodeDeployToECS アクションを使用して、ECS サービスに対して Blue/Green デプロイを行う
- CloudFormation デプロイアクションを使用してサービスの更新を行う
が挙げられると思いますが、今回は Blue/Green デプロイの手法を採用しました。 理由は、
- 他サービスのデプロイと並列実行が可能
- デプロイ方法が Blue/Green デプロイに統一できる
ためです。 一方、これには課題もあり、 Blue/Green デプロイのためだけにしか使われない ELB が必要になります。 これはAWSのサポートに機能要望として挙げたので、今後のアップデートに期待したいと思います。
16kB のログチャンクサイズ
これは、ハマったところです。
Fluent Bit 導入当初は アプリケーションコンテナはログを標準出力していました。 従って、アプリケーションログの転送経路は以下のようになります。
- アプリケーションコンテナ
- Fluentd Docker Logging Driver
- Docker Daemon
- Unix Domain Socket
- Fluent Bit コンテナ
※参考 aws.amazon.com
しかし、導入後しばらく経ってから、一部のログレコードが分割されていることに気づきました。 調査したところ、Docker 側の制限により 16kB でログが分割される 動作になることが分かりました。
※参考 github.com
解決策としては、(他にもあるかもしれませんが)
- Fluentd ロガーライブラリの導入
- 標準出力をやめて、Fargate タスクストレージにログファイルとして出力する
を考えていましたが、導入が容易だった後者を選択しました。*6
なお、タスクストレージを利用する場合は、 20GB の容量制限(プラットフォームバージョン1.4.0以降)があるので、定期的なタスク入れ替えやログローテーションの仕組みが必要になります。
最後に
2020年3月のプロジェクト発足から2020年11月に完了するまで、ずっと関わってきました。 正直な感想としては、無事に移行完了してホッとしています。
しかし、今の構成やデプロイ方法などがベストだとは思っていないので、 今後も運用しながら改善していきたいと思います。
お決まり
エンジニア募集しています!!!
カジュアル面談も可能なので、ぜひ遊びに来てください。
https://corp.toreta.in/recruit/midcareer/



)")
